Pratik Parekh
I'm a
- pratikparekh217@gmail.com
- +1 704 957 3422
- Charlotte, North Carolina, United State


I am a Graduate Student pursuing Computer Science from University of North Carolina at Charlotte. I completed my Bachelores in Computer Engineering. I am experienced in performing tasks related to Data Cleaning/Analysis , developing Machine Learning Algorithms and proficient in object - oriented languages such as Python, Java.I have published a research paper in Springer under the name "HECMI: Hybrid Ensemble Classifier for Multi-Class Imbalanced Data. I look to work in the field of Data Analysis/Science , Machine Learning or Software Engineering Also I am good at



Performed Web Scrapping to collect News and Twitter data using ‘Beautiful Soup’ & ‘Tweepy’.
Parsed this data to NLTK’s Sentiment Intensity Analyzer tool to get the sentiment score and combined this data with the next day’s closing stock price collected using API of ‘The World Trading Data’.
Artificial Neural Network and Long Short Term Memory (LSTM) were implemented to train the model using Keras.
Genetic Algorithm was incorporated with LSTM to find best weights and bias to reduce the RMSE value of the model.

Project Poster
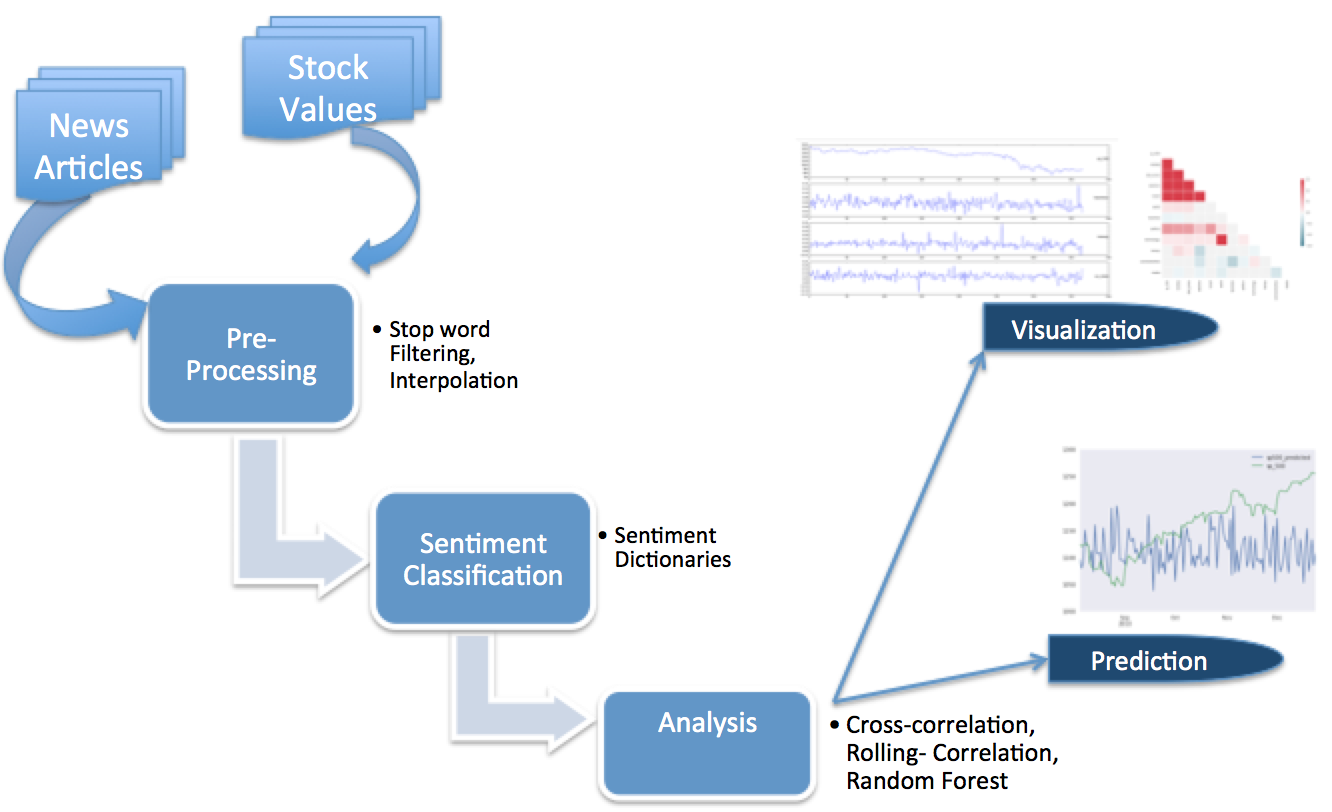
Model Flowchart
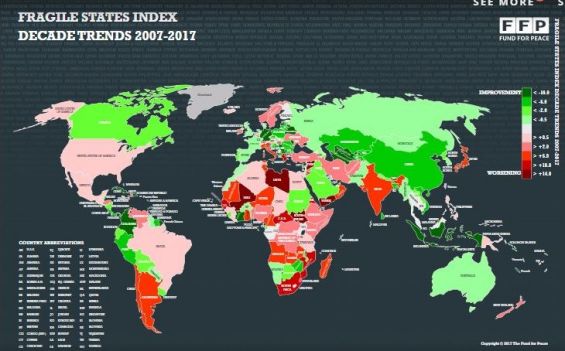
The FSI scores should be interpreted with the understanding that the lower the score, the better. Therefore, a reduced score indicates an improvement and greater relative stability, just as a higher score indicates greater instability. I performed the discretization on the decision feature as many null values were present. In this project, I have added 6 new features along with the 12 indicators of FSI. The data for these new features have been taken from the World Bank website. I have selected these new features based on the weight they add to the existing data. Very critical parameters have been intensely studied and chosen to determine the best precision.I perfomed below data cleaning and pre-processing tasks with the use of WEKA.
After completion of data pre-processing, I tried and tested a lot of classifiers in WEKA tool to get the best-suited classifier for our data. Few of the tested classifiers are as follows:
I have also used LISp Miner to find out Action rules.LISp-Miner is an academic project for support research and teaching of knowledge discovery in databases. In order to find the action rules antecedent variable and stable variables were chosen.Also, finalized the succedent variable and stable attributes.The decision attribute was chosen from the given data with values 'Alert' -> ‘Stable’ and 'Alert' -> 'Warning' as succedent variable. Rules were chosen with highest confidence were chosen which had the range from 0.8 to 1.00.
This action rules suggests what changes in values of classification features are needed to lower FSI.
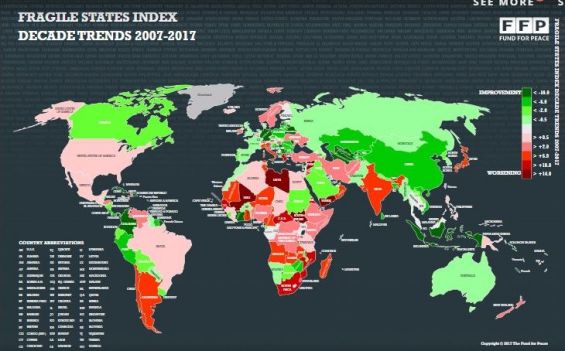
Fragile State Index
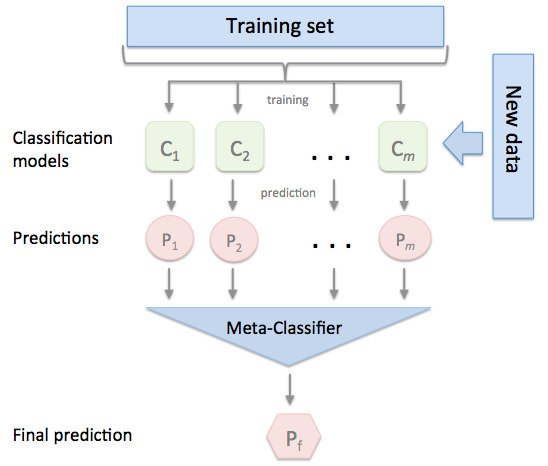
Implemented a hybrid ensemble classifier based on bagging and boosting techniques to classify multiclass imbalanced data.
Extracted data from CSV files using Python’s ‘Pandas’ library, manipulated data to feed the classifier for training using ‘Numpy’ library and used ‘Imblearn’ to implement Smote for balancing the imbalanced data.
Used ‘Scikit-learn’ for implementing traditional classification algorithms and compared them by building confusion matrix and calculating recall of minority class to select the best algorithm to make the base classifier.

Architecture of the Model
Implemented k means clustering algorithm to perform summarization of corpora and group them on the basis of similarity.
Performed data cleaning and preparation tasks such as removal of stopwords, numerical, special characters, implementing stemming and tokenization of words, removal of unusable documents using word clouds, etc.
Built the term - document matrix and calculated tf-idf weight for each token created in the corpora and to find significant tokens.
Implemented dendrograms and multi – dimensional scaling using ‘Matplotlib’ library for visualization of the document clusters and word clouds for validation of the results.

Multi-Dimensional scaling

Dendrogram
Designed a database on Insurance Management Systems by constructing an Entity – Relationship diagram of the model and created an AWS RDS Instance, connected it with MySQL Workbench for creation of the database.
Applied triggers, events, stored procedure and views to implement various functionalities of the system.
Developed User Interface for the system using PHP, HTML and Javascript & integrated SQL queries with the User Interface code.

Database Management System

{kind=link}
{kind=link}
{kind=link}
{kind=link}